
AI×HRでのリッチなメタデータ生成を、あらゆる動画に対応可能な支援サービスとして構築
~AIメインフレームによるDX推進、HRによるAI自動生成の弱点克服、コンテクストマッチ広告や映像資産のビジネス活用までトータルにサポート~
TV番組・CMデータの調査・分析・配信を行う株式会社エム・データ(東京都港区、代表取締役社長:薄井司、以下、エム・データ)は、各種生成AIや関連AIサービスを主軸に、エム・データの専門オペレーターによるデータ補正・補完スキルとメタデータ生成ノウハウ(20年の過去データ資産【TVメタデータ・ライブラリー、正規化されたマスタ・名詞辞書】や、人によるコンテクストやニュアンスなどの正しい意味・内容解釈、AIでの間違いや誤植の補正)を用い、あらゆる映像コンテンツからメタデータを生成し、リッチ化・高度化する取り組みを、テレビ局をはじめとする動画配信事業者と共に構築・運用するサービスを展開します。
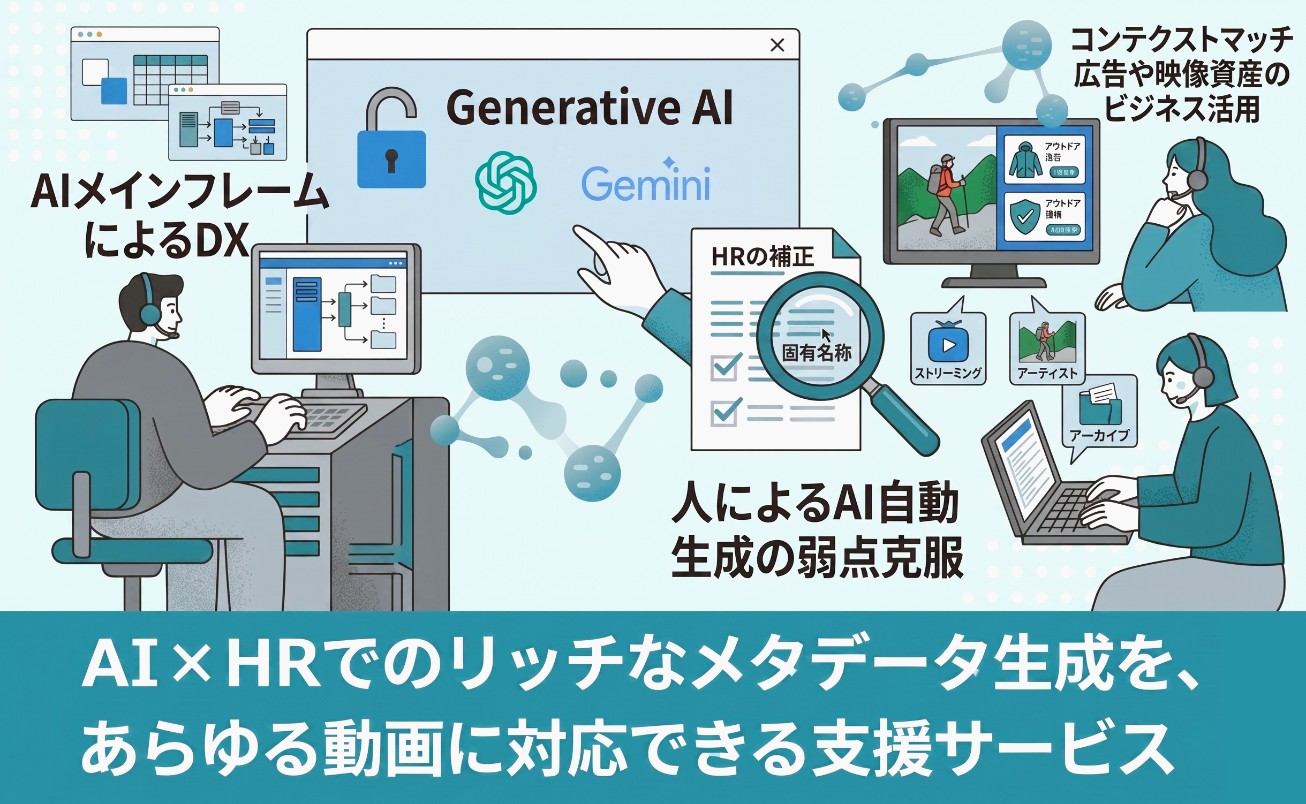
昨今、多くの動画配信事業者において、Claude、ChatGPT、Copilot、Geminiなどの生成AIや 、音声・楽曲認識、画像解析技術を駆使して動画コンテンツからメタデータを自動生成する取り組みが進められています。
しかしながら、実務の運用においては、AIが生成したデータの正確性の課題(例:固有名詞の誤認やハルシネーションが多く、人間による目視チェックと修正の手間が発生)や、莫大なAI処理コストの課題(例:アーカイブ向けにインデックスを作るだけで、膨大なコストと時間が掛かる。また自社コンテンツのデータしか揃わない等)、さらにはビジネスに直結する高付加価値なデータ生成の実現など、大きな課題が存在します。
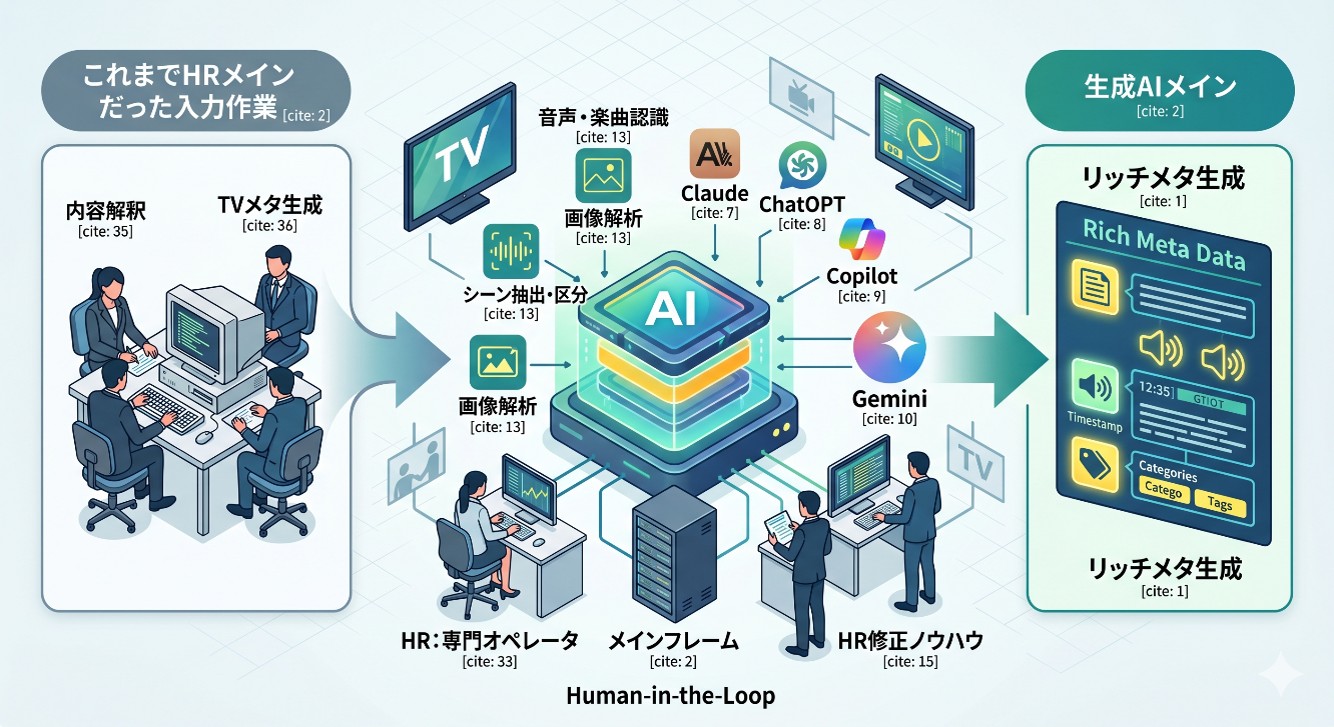
本サービスは、これまで人間(HR)が行ってきたデータ生成作業をAIメインのフレームへとシフトし、エム・データが過去20年以上にわたり蓄積したTVメタデータとマスタ(名詞辞書)に加え、専門オペレーターのノウハウを組み込む「ヒューマン・イン・ザ・ループ(Human-in-the-Loop)」体制で、高精度かつ低コストなだけでなく、ビジネス価値の高いリッチな動画コンテンツメタデータの生成・運用を支援します。
加えて、これまでのデータビジネス(収益化)の実績を活かし、「生成AI×TVメタデータ×マルチデータ」での新価値創造や共創も手掛ける予定です。
■エム・データによるデータ生成業務の課題解決ポイント
本サービスは、他社には真似できない独自のデータ処理アプローチにより、動画配信事業者のAI活用における「精度」と「コスト」の課題を同時に解決します。
① 人的生成メタデータの組み込みによる「正確なデータ生成」
AI単体だけでのデータ生成ではなく、人間(専門オペレーター)がこれまでに生成・蓄積してきた高品質なメタデータと、マスタ(名詞辞書)を「コンテクスト(前提情報・文脈)解釈」としてAIにインプットした上でデータ生成を行います。
これにより、AI特有の固有名詞・新語・略語・専門用語などの認識ミスや内容の誤認を防止し、AI単体では到達できない、放送文脈に即した高精度なTVメタデータの自動生成を可能とします。
② AI×HRのハイブリッド処理による「超高精度かつ網羅的なデータ生成」
①によって生成した高精度なAI生成データに対し、専門オペレーターが更なる品質チェックと不足情報の補完を行うことで、超高精度かつ網羅性の高いデータを生成することが可能となります。
③ 露出箇所の事前特定による「AIコストの低減」
番組内の特定のトピックや、特定企業のCMなどに限定してデータ生成を行う場合、エム・データがHRで生成した既存のメタデータを活用し、当該トピックやCMの露出箇所(タイムスタンプ)を予めピンポイントで特定します。
AIに番組全編を処理させるのではなく、特定された箇所のみをターゲットに処理させるため、不要なデータ処理を徹底的に排除し、AIの計算コスト・運用コストを大幅に低減させることが可能です。
■ 本サービスが提供する「3つのコア価値」 ※一部構想を含む
1. 【DX推進】AIメインフレームと専門オペレーターの協働(協働軸)
- これまで人間(HR)が主導していたTVメタデータ入力業務を、生成AIをメインとした効率的なワークフローへと進化
- 専門オペレーター(HR)による視聴・内容解釈のノウハウをAIのプロセスと融合させることで 、テレビ局や動画配信事業者内におけるメタデータ生成業務の精度担保と効率化を実現する体制構築を支援
2. 【課題解決】AI特有の弱点をカバーする「ミス補正&マスタ正規化」(実務特化軸)
- 生成AIが苦手とする、新語・略語・造語・専門用語・ローカル表現、初出人物や話題の認識ミスを的確に補正
- クロストークやBGM・ノイズの影響、同音異義・同名異人、コンテクスト解釈や話者特定といったAIの弱点に対し、専門オペレーターの補正ノウハウと、過去20年に渡り蓄積したデータを駆使して精度を向上
- 番組、人物、企業、商品ブランド、消費財などの固有名詞に対してラベリング(意味・属性付与)を行い 、正規化された一意のIDを付与して顧客要件毎の辞書・マスタ構築から定期メンテナンスまで対応
3. 【未来・価値創造】映像資産をマネタイズに繋げる「リッチメタ生成」(ビジネス展開軸)
- 単なる文字起こしや全文書起しにとどまらず、シーン分割・シーン区分(スタジオ/VTR/中継など)や内容要約、話者特定、話題の切替わり点(IN点/OUT点のタイムスタンプ)、CM判定などのカスタマイズにも対応
- 放送前メタ(放送予定コンテンツのデータ)やコンテクストマッチ広告(コンテンツの内容や文脈に連動した広告配信)に最適化された広告用メタデータ・タグ・アノテーション・コンテクストカテゴリー分類を生成
- 膨大な過去の映像資産を有効活用するための「アーカイブ・ライブラリー映像用インデックス」を構築(収録・未放送素材にも対応)
- 画面上のテロップ、フリップ、スーパー、エンドロールにいたるまで漏れなくデータ化し、映像資産のビジネス価値を最大化
- これまでのデータビジネス(収益化)の実績やユースケースを活かし、「生成AI×TVメタデータ」での新価値創造やビジネス化のサポート(産業・機能別のAIサービス構築。各AIやAI活用ソリューション、各社のAI基盤・AI機能、データプラットフォームなどとの連携)
※これらのコア価値を体感いただくための共同実験も計画しています。
■オープンな連携性
本サービスは、当社独自のAIシステムに限定されず、動画配信事業者が導入・活用するAI基盤やAIサービス、既存データプラットフォーム(AWS、Azure、Google Cloud、Snowflake等)と柔軟に連携する想定で、既存環境を活かしつつ、メタデータの精度向上とコスト削減を実現したいニーズにも柔軟に対応していく予定です。
また、これらを「(仮称)TVメタデータ MCP(※)」として推進する計画です。
(※MCP「Model Context Protocol」とは、GeminiやClaude、ChatGPTなどのAIを外部サービスやツールと安全に連携・接続させる際の共通ルール・統一規格のことで、AI利用者がAIと複数の外部ツールを簡単に連携できるようにするためのもの。)
■TVメタデータ生成におけるサポート機能例
本サービスでは、以下の高度なメタデータ処理・生成機能を組み合わせてご提供いたします。
【カテゴライズ・区分】
番組やCMを識別し、番組シーン(コーナー)ごとに抽出した上での正確なタイムスタンプやID付与
【内容・意味理解】
発話・楽曲・ナレーション・コピー等の音声認識や、テロップ・人物・物体・ロゴ等の画像解析を統合。これらをもとに見出しとサマリ文による要約作成、話題分類、コンテクスト付与、二次情報や付帯情報の付与(タギング)、カテゴリー分類
【その他・データ整備】
校正、表記揺れ補正、名寄せ、新語検知、話者区分、イレギュラー判定をはじめ、データのグルーピング、クラスタリング、集計、ランキング、各種マスタ統合(マッピング)に至るまで柔軟に対応可能。アウトプットのフォーマットや出力項目も任意に設定可能
■「AI×TVメタデータ」での新価値・新市場創造、共創、ビジネス化・マネタイズ事例
◇ TV露出銘柄の株価先行指標 (シグナル検知 ~ メディア・コンテンツパワーの指数化)
AIがTVメタデータから株価の初動を予測する「TV Alpha」で、市場(TOPIX)を上回る成果を確認 – エム・データ
◇ TVトレンド情報によるヒット商品予兆検知 (商品・メニュー開発、需要予測、販促、リテールメディア連携
TVメタデータ×生成AIでヒットやトレンドのシグナルを検知! エム・データと2WINS、トレンド検知AIエージェントの共同開発に着手 – エム・データ
■株式会社エム・データが提供する「TVメタデータ」とは?
株式会社エム・データでは、TV番組やTV-CMの放送内容(実績)をテキスト化(データベース化)した「TVメタデータ」を生成しています。データ生成センターでは常時40名前後の専属スタッフが24時間365日「いつ」「どこで」「何が」「どのように」「何秒間」放送されたかを、オリジナルのシステムを使用しデータベース化しています。
TVメタデータは、主に「①番組データ(番組放送内容)」「②TV-CMデータ(広告出稿内容)」「③アイテムデータ(番組で紹介された商品情報)」「④スポットデータ(番組で紹介された店・宿・観光地等の情報)」「⑤各種マスタ・辞書データ」などで構成され、ローデータ提供サービスの他に、ランキングコンテンツや調査・集計・分析のレポートサービス、分析結果を基にしたコンサルティングサービスなどがあります。
■株式会社エム・データについて
株式会社エム・データは、テレビ放送(番組およびTV-CM)の放送実績を独自にテキスト化したデータベース「TVメタデータ」を生成して、調査・分析・配信を行うデータプロバイダです。民放キー局(在京5局)等と資本提携し、業界基準のTVメタデータを構築しており、主なサービスには、「TVメタデータ」を提供する「①データ配信サービス」、お客様のご要望に応じて調査・分析を行う「②放送実績調査サービス」、放送された話題を露出・報道量で集計しランキング形式で提供する「③ランキングサービス」、ビッグデータ解析ツール「④TV Rank」の提供を通じ、企業のマーケティング支援、コンサルティングをしています。
「データで世の中やビジネスを面白く!」をパーパス(存在意義)として、様々な業界での課題解決にデータで貢献します。
■会社概要
株式会社エム・データ(M Data CO.,LTD)
住所 :東京都港区新橋1-12-9 新橋プレイス6階 ビジネスエアポート新橋内
URL :https://mdata.tv
設立 :2006年1月23日
代表者 :代表取締役会長 関根 俊哉
代表取締役社長 薄井 司